Figure 1.1—A Comparative View of AI, Machine Learning, Deep Learning, and Generative AI
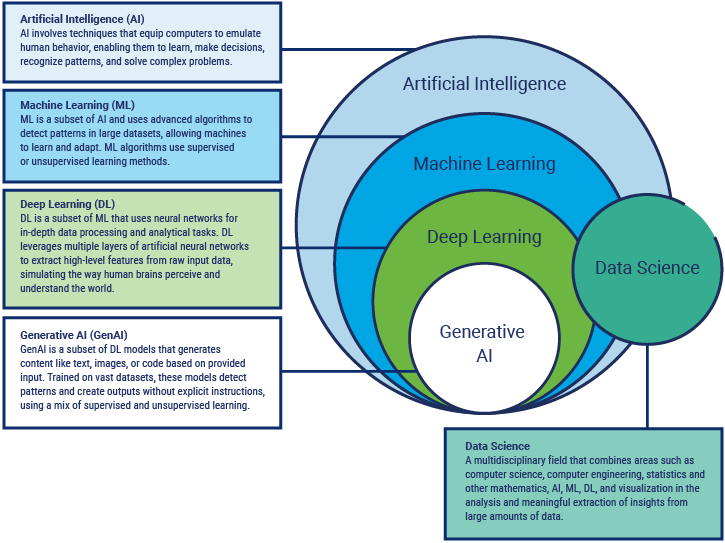
Source: ISACA, ISACA AAISM Official Review Manual, USA, 2025
The use of AI and AI-enabled technologies has drastically changed the current business landscape and the pace at which innovation and development occur. In order to ensure the effective use of AI, enterprises must understand the problem AI aims to solve, which can differ from enterprise to enterprise. For example, in healthcare, AI diagnostic tools must undergo continuous validation to ensure algorithmic accuracy, compliance, and ethical deployment. Once enterprises understand the types of AI solutions available and the risk associated with them, they can make informed decisions on which solution is best for the organization.
AI is an advanced computer system that can simulate human capabilities, such as analysis, based on a predetermined set of rules; these systems consist of algorithms that specialize in learning from data. AI is a broad term that encompasses everything from conditional “if-else” rule engines to modern applications, such as autonomous vehicles, and sophisticated computer programs, such as TensorFlow.
Machine learning (ML), a subcategory of AI, is a program or system that builds (e.g., trains) a predictive model from input data. The key word with ML is “data.” In practice, most of the applications classified as AI are, in fact, ML tools that leverage statistical models to summarize patterns from large datasets, which can later be used to make predictions in new data. Large models often require large datasets and specialized computing, which affects risk, cost, and environmental footprint.
Deep learning (DL), a type of ML, is a multilevel algorithm that gradually identifies things at higher levels of abstraction (e.g., image classification).
AI and ML innovation began decades ago. However, these technologies have attracted significant industry attention recently, thanks to advancements in DL that outperform traditional ML—such as logistic regression, support vector machines, and random forest classification—in the application of computer vision, language translation, speech recognition, and more.
Generative AI (GenAI), a subset of DL models, is a transformative branch of AI that has the capability of generating new and original content, including images, code, text, speech, translations, music, and art.1 See 1.1.3 Generative Models for more information.
AI, ML, and DL have a hierarchical relationship, which is depicted in figure 1.1.
AI can be categorized according to functionality or distinguished by capability. There are four types of AI based on functionality: reactive machines, limited memory, theory of mind (ToM), and self-aware AI. The four functionality-based types can also be viewed through the lens of capability (e.g., artificial narrow intelligence [ANI], artificial general intelligence [AGI], and artificial superintelligence [ASI]).
AI models (e.g., Chat Generative Pretrained Transformer [ChatGPT]) are created to generate outcomes using one or more AI systems. ML models are constructed using one or more algorithms, and their primary purpose is to learn from data and make predictions or decisions based on that data2 without being explicitly programmed to do so.
Note
This section provides an overview of AI models and technologies currently used. AI technology is rapidly evolving, so the candidate is encouraged to review external sources to keep up to date on trends and advances in AI.
Figure 1.1—A Comparative View of AI, Machine Learning, Deep Learning, and Generative AI
Source: ISACA, ISACA AAISM Official Review Manual, USA, 2025
AI encompasses a wide range of functionalities and capabilities. These functionalities, which cover what AI does, can be broadly categorized into four distinct types, as shown in figure 1.2.
Each type of AI functionality represents a different level of complexity and sophistication in AI systems and plays a vital role in determining the capabilities and potential applications of AI technologies. Collectively, these functionalities provide a helpful framework for understanding the diverse landscape of AI.
In addition to the four primary types of AI functionalities, it is important to recognize the emergence of new functionalities that are expanding the AI landscape. While not yet distinct categories, these emerging functionalities represent significant advancements in AI technology.
Figure 1.2—Types of AI Based on Functionality
| Functionality Type | Overview | Risk/Limitations | Examples |
|---|---|---|---|
| Reactive machines | Reactive machines, one of the earliest and most basic forms of artificial intelligence (AI) systems, have played a significant role in the advancement of modern AI. Their evolution can be traced back to the early days of computing, when simple rule-based systems were developed for performing specific tasks.3 Reactive machines operate by automatically generating a response to a specific, limited set of inputs. Their functionality is modeled after the human mind’s capability to react to various stimuli. |
|
|
| Limited memory | Limited memory is a variant of AI characterized by its brief memory recollection. While it can use observational data from its most recent experiences for a specific task, it cannot store intricate repositories of past experiences. Limited memory AI machines possess a static memory repository to preserve a specific rendition of the world, which allows them to master certain tasks. They are also equipped with dynamic memory, which briefly stores information on recent experiences, such as browser history from the past three days. |
|
|
| Theory of mind (ToM) | ToM is a concept within the field of artificial general intelligence (AGI) that encompasses the creation of machines capable of understanding and mimicking human thought patterns, ideas, and decision-making processes. To create machines with a ToM, it is necessary to embed in them the understanding that thoughts and emotions impact human behavior. This means the machines must have a deep understanding of social interactions and be able to identify, understand, retain, and remember emotional responses. By processing human commands and adapting them to their learning centers, these machines can start to grasp the rules of basic communication and interaction. |
|
Note These are early examples of ToM and do not constitute full ToM functionality. |
| Self-aware AI7 | A form of artificial superintelligence (ASI), self-aware AI applies to machines that are not only aware of the emotions and mental states of others but also their own. Although human consciousness in machines has not been achieved, cutting-edge advancements at an unprecedented pace are propelling developers closer to self-aware AI. The development of self-aware AI is a monumental task that requires a deep understanding of human consciousness, emotions, and desires. With recent advancements in neural networks (NNs), deep learning (DL) algorithms, and natural language processing (NLP), AI research is rapidly progressing toward the goal of self-aware AI. | Still theoretical | None currently |
Source: ISACA, ISACA AAIA Official Review Manual, USA, 2025
Reviewing AI capabilities, to understand how well or to what extent it performs a task, involves monitoring progress in ANI and the current state of AI and anticipating advancements toward AGI. Eventually, through these means, the emergence of ASI may be possible.
ANI is a form of AI that is limited to a specific domain or area of knowledge. Dubbed “weak AI,” ANI simulates human cognition. It has the potential societal benefit of automating time-consuming tasks and analyzing data “in ways that humans sometimes can’t.”8 Additionally, ANI “lacks self-awareness, consciousness, emotions, and genuine intelligence that can match human intelligence.”9 In other words, ANI systems can do their specified duties with a high degree of accuracy and efficiency; however, their intelligence is limited in scope.
Given their limited intelligence, these AI systems can only perform specific tasks related to a narrow domain. For example, an AI system that has been trained for language translation operates within the language domain, while an image classification AI system operates within the image recognition domain. Each domain is defined by the specific tasks the AI system was designed to carry out and the data used to develop it, which determines the scope of its abilities.10 Narrow AI can be classified as reactive or limited memory AI, as described in figure 1.2.
Most AI falls into the limited memory category, allowing machines to use large amounts of data, particularly in DL domains, to produce highly accurate results.11 Examples of ANI include cell phone applications such as Siri or Bixby, facial recognition, and AI assistants such as Google Assistant. One of the more common applications is autonomous vehicles.
Autonomous vehicles typically employ a combination of multiple ANI systems to facilitate smooth operation, even in complex environments, such as crowded urban areas. They rely on cameras and sensors to provide information about the vehicle’s surroundings and make operating decisions by feeding the data into computer vision algorithms that help the vehicle interpret, understand, and navigate its environment based on informed decision making. For navigation, the AI system embedded in the autonomous vehicle makes use of a global positioning system (GPS) to locate the vehicle and provide access to maps so it can plan a safe and efficient route to the destination by evaluating all possible routes and considering factors such as obstacles, heavy traffic, road closures, and hazardous weather conditions. Connected to the internet, autonomous vehicles make it possible to share information with cloud services and surrounding vehicles. Internet connectivity also enables regular vehicle updates and maintenance.12
Despite the limitations of ANI, its impact on society and the field of AI technology is significant. ANI system development and deployment continue to affect a wide range of applications, laying the foundation for future advancements in AI research.
AGI is a type of AI characterized by its capability to undertake any intellectual task a human can perform.13 The timeline for AGI is still uncertain, but researchers and experts agree that its potential impact on society and human life means that even a small probability of its arrival should be taken seriously.
To qualify as AGI, an AI system needs to possess the following capabilities:14
Currently, AI developers are making significant progress in computer vision and natural language processing (NLP), but critical capabilities are still necessary for AGI to reach a level of intelligence on par with humans, including mastery of fine motor skills, common-sense knowledge, and social-emotional engagement.15
ASI represents a hypothetical future stage of AI that transcends human intelligence. Unlike traditional AI, ASI would not only be able to do any intellectual task that humans could do but would also surpass human capabilities to achieve what were once thought of as impossible feats. ASI’s potential to solve complex problems, create groundbreaking innovations, and generate novel solutions with unparalleled speed and precision would set it apart from any other form of intelligence known to humanity. Figure 1.3 depicts just some of the potential capabilities of ASI.
Figure 1.3—Human-like Capabilities of Artificial Superintelligence
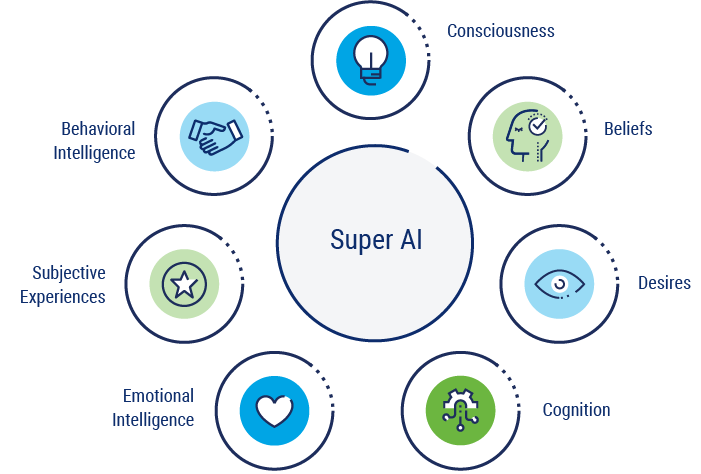
Source: ISACA, Artificial Intelligence: A Primer on Machine Learning, Deep Learning, and Neural Networks, USA, 2024
While ASI remains a theoretical concept at present, experts anticipate that advances in technology will eventually make it a reality, forever changing the course of human history. The emergence of ASI could usher in a new age of prosperity, progress, and exploration that will stretch the limits of human imagination.
GenAI refers to models capable of producing novel content, such as text, images, audio, or code, based on learned patterns from training data. To truly grasp the transformative power of GenAI, it is essential to understand the generative models that serve as its foundation.
Among these, the emergence of general adversarial networks (GANs) stands out as a revolutionary development that has significantly impacted various fields. Representing an innovative class of DL models, GANs use a dual neural network (NN) system, where a generator and discriminator network are trained at the same time and compete against each other. The generator network creates entirely new data samples that closely resemble the data on which it was trained, while the discriminator network focuses on distinguishing between the generated samples and the original samples. The key benefit to this adversarial approach is that as the training progresses, the performance of both networks continuously improves until the generator is eventually able to produce new data that is so realistic that the discriminator cannot reliably differentiate it from real data.16 An example might be the model being able to complete an image for which little information was initially fed into it. GANs have served as a catalyst for numerous breakthroughs, such as the creation of high-quality images and videos, transference of artistic style, augmentation of data for ML, text-to-image synthesis, and realistic voice synthesis.
GenAI and generated content are subject to legal and ethical risk, and GenAI developers have a unique role in the associated ethical dilemmas. For example, the potential distribution of harmful content generated by their platforms could prove detrimental to society and expose them to legal actions. Similarly, copyright ownership, infringement, and intellectual property (IP) concerns are elevated with the use of GenAI. GenAI systems may replicate bias, generate harmful or misleading content, and violate consent boundaries if not properly aligned. Developers must go beyond traditional AI safeguards by implementing content gating, distribution protocols, and continuous risk monitoring in consultation with the data owners for extra validation.
Agentic AI refers to the current iteration of AI assistants and related technologies. AI agents are AI systems that are able to make autonomous decisions and act to achieve specific objectives, such as improving customer satisfaction scores or maximizing supply chain efficiencies.17 AI agents consist of three components: a large language model (LLM), knowledge base, and enterprise tools (figure 1.4).
Use cases for agentic AI include:18
Possible benefits of agentic AI include:19
Figure 1.4—Components of Agentic AI
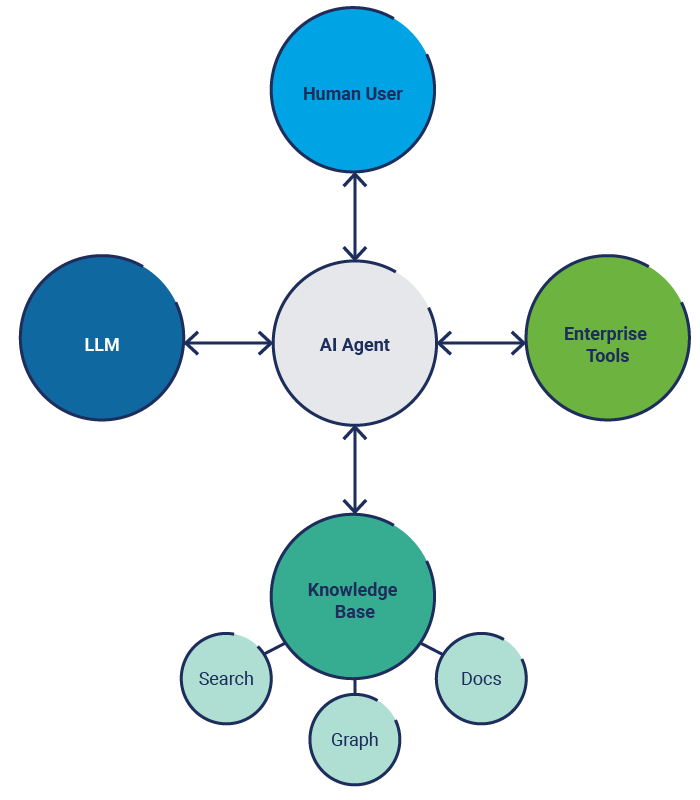
Source: Murali, A.; “Safeguarding the Enterprise AI Evolution: Best Practices for Agentic AI Workflows,” ISACA Industry News, 1 July 2025, link
As with any emerging AI solution, agentic AI also comes with new risk:20
Agentic AI is rapidly evolving and requires human oversight to optimize its effectiveness. For example, poorly articulated goals and objectives can greatly impede the success of an AI agent in completing its tasks. This human oversight grows more difficult as the network of AI agents increases.21 As this network grows, isolating and identifying which AI model or models are producing inaccurate outputs is not as straightforward as it is with narrow AI configurations. Upskilling must include scenario modeling, credential hygiene, traceability validation, and escalation protocols.
From a risk perspective, knowing when and where to perform risk assessments on these complex systems, as well as what team or individuals are responsible for those assessments, becomes increasingly difficult. Training and upskilling teams to be able to monitor and react to potential issues within agentic AI in real time is key.22
Predictive AI models use historical data and ML algorithms to forecast events and trends. These models analyze past data to identify patterns and relationships, which can then be used to make decisions based on identifiable future trends or patterns. Predictive models have a wide range of applications, including predictive maintenance in manufacturing, financial forecasting, and making improvements to threat detection and overall security measures.
There is unique risk associated with the use of predictive models, particularly when leveraging them to make business decisions. AI developers and users need to ensure they fully understand the data flow and integrity controls from the source systems being input into the model, as well as data completeness, accuracy, and cleansing methods for using data to train and then put through the models. Predictive models must be audited for bias, drift, and overfitting, especially when used in high-stakes decision environments. Developers must ensure that prediction outputs are traceable to input features and training logic, with documented reasoning paths.
ML is an innovative subfield of AI that employs models and algorithms to enable machines to learn from data without explicit programming. These models and algorithms are based on various mathematical concepts, such as statistics, probability, linear algebra, calculus, and optimization. As an essential component of data science, ML leverages advanced statistical methods to develop robust algorithms capable of solving complex problems. One of the more common ML applications is the use of tools to monitor network traffic and system behavior for unwanted activities or violations of a security policy.
ML algorithms are vital for extracting valuable insights from large and diverse datasets used in applications such as pattern recognition, classification, anomaly detection, and predictive analytics. The advent of big data—generated by a myriad of technological devices, social media platforms, sensors, lidar detectors, and other technologies—has exponentially increased the volume and complexity of data available for analysis. This increase in data has led to continuous improvements in ML algorithms and their predictive accuracy.
Understanding the inner workings of AI algorithms improves the design and implementation of AI systems, helping these systems to better solve specific problems and achieve desired outcomes. Additionally, understanding these algorithms can help users identify potential limitations or biases in a system and take steps to address them. This knowledge is crucial for fully realizing the potential of AI technologies and using them effectively.
ML models evolve and enhance their performance over time. As models are trained with more data, real-world scenarios, and fine-tuning techniques, they improve in identifying patterns and making accurate predictions.
ML is considered a subset of the broader concept of AI. Within the concept of ML is the concept of NNs, which leads to the concept of DL.
ML techniques lend themselves to making predictions and automating tasks traditionally accomplished by humans. There are three main ML paradigms:
These paradigms form the foundation of this complex field of ML models, along with various other methodologies and techniques. By learning from vast amounts of labeled and unlabeled data and making highly accurate predictions through complex algorithms, ML is uniquely positioned to accelerate advancements in various fields.
In ML, labels refer to the known outcomes or categories a model is trained to predict. For example, in a computer vision model trained to recognize animals, the labels might include cat, dog, rabbit, snake, etc. However, in some scenarios, attaching labels may be challenging. Labels might be missing or hard to acquire for several reasons:
Supervised ML uses labeled data provided automatically by source systems or manually by data scientists to teach models how to reason and predict. The main feature of this method is that it maps input data to an output label. This helps the machine learn from correlations between inputs and outputs. One of the most significant benefits of supervised learning is that it enables a machine to make predictions or act on new, unknown data based on its understanding of the relationships between inputs and outputs from the labeled data it was trained on.
Supervised learning algorithms are classified into two types:
There is a distinction between regression and classification challenges. The results of regression are quantitative, whereas the results of classification are qualitative. The model to choose is influenced by the attributes of the dataset and the associated tasks.
Supervised learning models rely heavily on human involvement to operate successfully. When evaluating an ML algorithm based on a supervised learning model, it is important to remember the data- and human-related risk. Data quality and bias-related concerns should be considered the greatest areas of risk for this type of model, as supervised learning requires large amounts of high-quality data that is complete, accurate, and free from as much bias as possible. Modelers should complete a thorough source data analysis for completeness, correcting data types, treating missing information, removing duplicates or outlier data points, determining if synthetic data is needed, determining if data masking is necessary, etc.
Generally used for the same goals as supervised learning, semisupervised learning uses both labeled and unlabeled data. This is particularly beneficial when training a model where labeled data is limited or where labeling the data is tedious, labor intensive, or expensive. By introducing more related data (unlabeled), the model relies on assumptions to better understand the problem space.
Based on the concept of “ground truth” from supervised learning, self-supervised learning algorithms use pretext tasks to generate their own labels from unstructured data. Self-supervised learning is typically used in the field of computer vision where large amounts of data are required and labeling is difficult or costly.
What sets unsupervised learning apart from other learning methods is its ability to learn from unlabeled (raw) data, without explicit guidance or human intervention. One important takeaway of labeled vs. unlabeled datasets is that it will drive the type of model that is selected for an AI-enabled implementation. Unsupervised learning algorithms excel at detecting underlying patterns, relationships, and structures within raw, unlabeled datasets.25
Unsupervised learning algorithms operate without the need for labels in datasets. They detect and correlate commonalities based on the presence or absence of shared characteristics in each new piece of data, allowing a model to cluster similar data points, reduce the dimensions of high-dimensional data, identify anomalies, and establish association rules among data points.
Types of unsupervised learning algorithms are shown in figure 1.5.
Figure 1.5—Types of Unsupervised Learning Algorithms
| Type | Definition |
|---|---|
| Clustering methods | These are methods that identify and group together data points that share similar characteristics. The objective is to organize datasets so that data points within a particular group (or cluster) have more similarities among themselves than with the data points in other groups. Examples of clustering methods include exclusive or centroid-based clustering, overlapping clustering, hierarchical clustering, density-based clustering, spectral clustering, and distribution-based clustering.26 |
| Association rules | This technique is used to uncover how items within large datasets are associated with each other. It is a form of rules-based machine learning (ML) that reveals the probability of relationships between data items. An example is the Apriori algorithm. |
| Dimensionality reduction | This is a process that transforms high-dimensional data into a lower-dimensional space with the aim of simplifying the data while retaining its essential features. The goal is to reduce the complexity of the data, making it easier to work with and understand, without losing important information. Techniques used for dimensionality reduction include locally linear embedding (LLE), t-distributed Stochastic Neighbor Embedding (t-SNE), Isomap embedding, multidimensional scaling (MDS), principal component analysis (PCA), and uniform manifold approximation and projection (UMAP).27 |
Source: ISACA, Artificial Intelligence: A Primer on Machine Learning, Deep Learning, and Neural Networks, USA, 2024
Risk associated with unsupervised learning includes a lack of explainability of the results generated by the system. When evaluating unsupervised learning models, it is important to include a human in the loop (HITL) to ensure the accuracy and reliability of system outputs. See 3.13.3 Safety and Human Oversight for more information.
Reinforcement learning (RL) focuses on autonomous decision making and control tasks, which may include both digital and physical environments. It trains intelligent agents to perform tasks or achieve goals in a specific, complex, and uncertain environment by maximizing the expected cumulative reward.28
Unlike other ML approaches, RL learns autonomously from the consequences of its actions (e.g., rewards or penalties). RL is gradually being explored in security applications, which benefit from RL’s capacity to adapt in real time and learn optimal strategies through interaction with dynamic threat environments.
The most fundamental representation of RL is teaching a dog a new trick—rewarding it with a treat when it performs an action that is a step closer to the goal and withholding a treat when the action moves away from the trick. Over time and many iterations, the dog learns to associate correct actions with rewards in order to master the new trick. RL operates on a very similar principle, but in a computational setting, with a numeric value being the “reward.” An example of RL as a security tool is its use in adaptive intrusion detection. The system learns to detect and respond to real-time risk. Another example is within malware analysis. In a controlled environment, RL allows the model to execute and study malware to develop countermeasures.
Risk associated with RL is due to the autonomous nature of the model. When evaluating RL models, it is imperative to consider safety and ethics during the exploration phase. Leveraging HITL principles can help ensure that the actions a model may rely on in production are sound prior to introducing potential harm.
NNs are a complex collection of algorithms designed to mimic the way the human brain functions, with the goal of identifying patterns and making sense of the data they are fed. Just like humans, NNs learn from the information they process. As they sift through data, they adapt and refine their understanding, getting better at their tasks with each iteration. They are capable of generalizing patterns across tasks when trained on sufficiently large and diverse datasets, enabling flexible model application.
There are three general layers in a neural network (figure 1.6):
Figure 1.6—Layers of a Neural Network
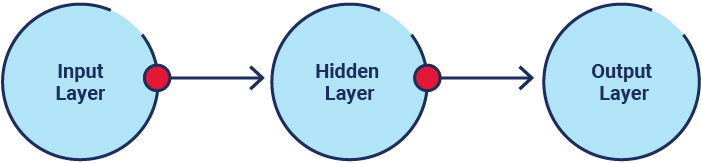
Source: ISACA, ISACA AAIA Official Review Manual, USA, 2025
In artificial NNs, hidden layers are situated between the input and output layers. These layers are termed “hidden” because their neurons do not have direct exposure to the input data or the final outputs; instead, they process signals received from the input layer and transmit results to the output layer. The primary function of hidden layers is to enable the NN to learn and model complex patterns and relationships within the data, facilitating the NN’s ability to perform tasks such as classification, regression, and feature extraction.
In the context of NNs, neurons are the fundamental units that process information. Each neuron receives input, applies a mathematical operation (typically represented as a weighted sum followed by an activation function), and passes the result to the next layer. In hidden layers, these neurons transform input data into intermediate representations, enabling networks to learn complex patterns and perform tasks such as classification or prediction.
Some examples of NNs are shown in figure 1.7.
Figure 1.7—Examples of Neural Networks
| Neural Network Type | Description | Examples |
|---|---|---|
| Feedforward neural networks (FNNs) | The flow of information is in one direction—from the input layer to the output layer—with no loops or feedback. Mainly used for tasks like image classification and regression problems, FNNs are not suitable for tasks requiring contextual memory or sequential data handling. |
|
| Recurrent neural networks (RNNs) | Designed for sequential data, such as time-series data, with loops that allow information to pass from one step of the sequence to the next, RNNs are effective in carrying out tasks like language translation and speech recognition. |
|
| Convolutional neural networks (CNNs) | Specialized for processing grid-like data, such as images, CNNs use convolutional layers to detect patterns such as edges, textures, and objects in images. They are widely used in computer vision tasks such as image classification, object detection, and video analysis. |
|
Source: Joy, A.P.; “The Differences Between Neural Networks and Deep Learning Explained,” Skill Camper, 3 January 2025, link
NNs are fundamental components of DL. An NN of more than three layers, including the inputs and the outputs, can be considered a DL algorithm (figure 1.8).
Figure 1.8—Deep Neural Network
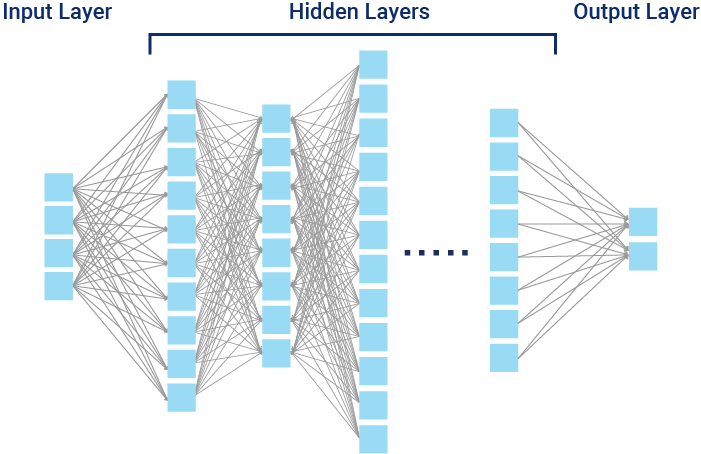
Source: ISACA, Artificial Intelligence: A Primer on Machine Learning, Deep Learning, and Neural Networks, USA, 2024
One of the key advantages of DL is its ability to perform feature extraction and transformation autonomously. This capability enables models to achieve high levels of accuracy and generalization with respect to NLP, computer vision, and autonomous systems.
Neural architecture search is an automated approach to creating the optimal NN for a given problem.29 There are a few approaches to neural architecture search, but most methods consist of three main components:30
While often lauded as “AI creating AI,” neural architecture search relies on human input and oversight to work with an AI solution to solve the problem presented.
Algorithms play a fundamental role in the field of ML and AI. Understanding the basics of algorithms is a foundational knowledge point to help understand risk related to AI solutions.
An algorithm is a set of step-by-step instructions or rules to be followed to solve a specific problem or perform a particular task.32 Algorithms are integral to computer programming and are designed to process data, perform calculations, and reach desired outcomes. In the context of ML, and AI at large, algorithms serve as the building blocks that enable models to analyze data, identify patterns, and make predictions.33 Each algorithm has associated hyperparameters—settings that can be adjusted prior to training the model to optimize its performance.
In AI, algorithms guide models in learning from data, identifying patterns, and making decisions or predictions based on that learning.
Hyperparameters guide the learning process by influencing the way the algorithm operates (e.g., the learning rate or the depth of decision trees in certain models). For example, an ML model for image classification may use a convolutional neural network (CNN) algorithm to extract and learn features from images and make predictions about their content. This is completed with specific hyperparameters that determine the number of layers in the network and how fast the model learns.
The ability of an ML model to adapt and improve over time is facilitated by the underlying algorithms that iteratively refine the model’s performance based on training data. This adaptability makes ML models invaluable tools for a wide range of applications, such as predicting customer behavior, diagnosing medical conditions, automating manufacturing processes, and understanding natural language. Powered by carefully chosen algorithms and well-tuned hyperparameters, ML models empower enterprises and individuals to leverage data-driven insights for informed decision making and enhanced productivity.
When training an ML model, selecting the right hyperparameters can often be as important as choosing the right algorithm.
It is important to ensure the correct type of algorithm is chosen to fulfill an AI’s intended purpose. Leveraging an algorithm that does not fully support it may lead to inefficiencies or issues with accuracy of an AI solution’s output. Figure 1.9 provides some examples of common algorithm classes and related use cases.
Figure 1.9—Common Classes of Algorithms
| Class | Algorithm Class | Description | Example |
|---|---|---|---|
| Supervised | Linear regression | A simple yet robust algorithm in the realm of supervised machine learning (ML). It models the relationship between a dependent variable and one or more independent variables by fitting a linear equation to observed data. | Predicting home prices |
| Logistic regression | Designed to predict the probability of an event occurring based on one or more independent variables. This makes logistic regression particularly useful for binary classification tasks. | Email spam filtering | |
| Tree-based models | Able to manage complex and nonlinear relationships between input variables and a target variable. These models use decision trees to show how input variables can predict a target value. Recursively splitting data by input variables creates a hierarchical structure that makes predictions at the leaf nodes. Tree-based models can classify data into categories, predict numerical outcomes, identify important features, and visualize decision processes. | Credit risk assessment | |
| Support vector machines | Commonly used for classification and predictive modeling tasks. The algorithm relies on establishing a decision boundary called a “hyperplane” (e.g., two sets of labeled data). These algorithms can work reliably with relatively small amounts of data. | Image classification | |
| K-nearest neighbor (K-NN) | Classifies inputs based on their similarity to nearby neighbors. The algorithm execution is refined by picking how many neighbors to examine (k) and some notion of distance to indicate how near the neighbors are. | Facial recognition | |
| Naive Bayes | From the Bayes Theorem, the simplest of all the Bayesian probability techniques—hence the “naive” reference. Naive Bayes applies to a collection of algorithms that share a common principle: that every feature classified is independent of the value of any other feature (attribute weight is equal). Its accuracy is not the most reliable—except in document and text classification, where it excels. | Spam detection | |
| Unsupervised | K-means clustering | This algorithm operates by initially choosing a predefined number (K) of cluster centers, known as centroids. The most recognized method within exclusive clustering.34 | Customer marketing campaigns |
| Hierarchical clustering | A hierarchy of clusters is generated, starting either with all data points as individual clusters and merging them (agglomerative approach) or with all data points as one single cluster and then dividing them into separate clusters based on dissimilarities (divisive approach).35 | Human gene mapping | |
| Principal component analysis | A statistical method that transforms the original variables into a new set of variables called principal components. These principal components are orthogonal (uncorrelated), and they reflect the maximum variance in the data. The first principal component reflects the most variance, the second principal component (orthogonal to the first) reflects the second most, and so on.36 | Image classification | |
| Reinforcement learning (RL) | Q-learning | A model-free RL algorithm that seeks to find the best action to take given the current state. It learns the value of state-action pairs, known as the Q-values, which represent the expected utility of taking a given action in a given state and following the optimal policy thereafter. By iteratively updating the Q-values (maintained in a Q-table) based on the rewards received, Q-learning gradually converges with the optimal policy without requiring a model in the environment. | Robotic path planning |
| Deep Q networks (DQNs) | An extension of Q-learning that uses deep learning (DL) techniques to handle high-dimensional state spaces. Instead of maintaining a Q-table, which is impractical for large state spaces, DQNs use a neural network (NN) to approximate the Q-values. It is an NN that takes the current state as input and outputs the Q-values for all possible actions. By leveraging the power of DL, DQNs can scale to complex environments. | Enhanced autonomous driving | |
| Policy-based | Policy-based methods directly learn the policy, which is a mapping from states to actions. Instead of learning a value function and then deriving a policy, these methods directly optimize the policy function. | Robotic arm control |
Ensemble modeling may be used in ML to minimize single model or dataset limitations, such as bias, high variability, and inaccuracies. Ensemble modeling uses multiple ML algorithms to train several models, which can improve the accuracy of predictive analytics and ML outcomes.37 Ensemble models have been used in healthcare and data mining applications.
Examples of ensemble modeling techniques include:38
Some additional technical terms and concepts that risk professionals should be familiar with are explained in figure 1.10.
Figure 1.10—AI Considerations
| Concept | Explanation |
|---|---|
| Large language models (LLMs) | AI systems trained on vast amounts of data (usually textual data) that use a neural network (NN) architecture called a “transformer” to process and weigh the relation and importance of sequences of input to learn to understand and generate human-like responses. Inputs can include books, articles, code repositories, or electronic documentation and files. LLMs are currently used commercially in functions, including summarization and translation services, and in applications such as chatbots.39 |
| Small language models (SLMs) | NLP models that are “lightweight,” with fewer parameters compared with LLMs; they are intended to be more resource effective than LLMs. They are commonly used for narrow and specific tasks in mobile apps, chatbots, and consumer hardware.40 |
| Prompts | Inputs often created by humans that initiate the output in generative artificial intelligence (GenAI) systems. The subjective measure of quality assigned to a GenAI output is often mistaken as a flawed or incomplete response from the model, but the accuracy of the output is often directly related to the specificity of the prompt. Prompt creation resources41 are available to help humans ask better questions of GenAI. |
| Foundation models | Sometimes referred to as general-purpose AI (GPAI), foundation models are trained on broad datasets and can be adapted to a variety of tasks. Current uses range from generating original artwork and writing to composing music and discovering new drugs and molecules.42 These models can also provide the theory and methods for analyzing and mitigating cyberthreats. |
| Transformers | An AI model architecture that uses “attention” to collect relationships in data, particularly language. An attention layer is a nonlinear operator that maps a collection of tokens to new representations by computing weighted combinations of input vectors, where the weights (attention scores) reflect the relevance of other tokens to each token.43 It processes information simultaneously, leading to faster learning and the completion of tasks like translation and text generation. |
| Natural language processing (NLP) | An AI branch that enables computers to understand, interpret, and generate human language. NLP combines computational linguistics, machine learning (ML), and deep learning (DL) models to process and analyze large volumes of text and speech data from sources such as files, emails, social media, spoken commands, and audio recordings. NLP is fundamental for tasks like speech recognition, text classification, and sentiment analysis, allowing for real-time interaction between humans and models.44 |
| Sentiment analysis | Also called “opinion mining,” the capability, based on NLP, text analysis, computational linguistics, and biometrics, of analyzing large volumes of data, to determine whether it expresses a positive sentiment, a negative sentiment, or a neutral sentiment. This analysis classification is referred to as polarity. Types include:45
|
| Underfitting | The ML model under development is too simplistic to identify the patterns in the data used for training. Model performance is usually poor for both training data and test data outcomes. Inaccurate predictions will show bias. Processes need to be in place to evaluate the cause to identify underfitting and determine a solution.46 |
| Overfitting | The model has been trained too precisely so that it “memorizes” the data, including the noise, outliers, and errors. An overfit model displays excellent performance on training data but poor performance on new data. As with underfitting, processes should be in place to train and analyze the training and test results to determine if overfitting is occurring. Bias can occur when an overfit model is deployed and makes faulty predictions on new data. |
| AI as a service (AIaaS) | AIaaS is a category of cloud-based services that allow enterprises to access AI tools through subscriptions. In AIaaS, the organization does not know how the model was developed or have access to its infrastructure. While the easiest to deploy, AIaaS is not without risk that needs to be considered. |
The rapid advancement and adoption of AI technologies have introduced complex challenges related to governance, risk management, ethics, and compliance. To address these challenges and support responsible AI (RAI) deployment, several key AI governance and risk management frameworks have been developed by governments, standards organizations, and industry groups. These frameworks provide structured guidance to help organizations identify, assess, and mitigate AI-specific risk while aligning AI initiatives with ethical principles and regulatory requirements.
AI frameworks are useful tools when integrating AI into an enterprise’s existing governance and enterprise risk management (ERM) program, as they can complement frameworks currently used and provide guidance on AI-specific considerations that are applicable to the enterprise’s objectives and vision. Some examples of AI-specific standards and frameworks are shown in figure 1.11.
Note
Candidates will not be tested on specific AI frameworks or standards. However, it is important to understand some of the underlying principles and concepts introduced by these frameworks and how frameworks can be integrated into existing governance programs and leveraged to establish AI governance within an enterprise.
Figure 1.11—Examples of AI-specific Standards and Frameworks
| Title | Description |
|---|---|
| ISO/IEC 23053: Framework for Artificial Intelligence Systems Using Machine Learning | A standard published by the International Organization for Standardization (ISO) for describing a generic artificial intelligence (AI) system using machine learning (ML) technology |
| ISO/IEC 42001: Information Technology—Artificial Intelligence—Management System | A standard that focuses on ethical use, transparency, and accountability in AI governance. It outlines an IT AI management system and the requirements for establishing, implementing, maintaining, and continuously improving it. |
| IEEE 7000-2021: IEEE Standard Model Process for Addressing Ethical Concerns during System Design | A standard published by the Institute of Electrical and Electronics Engineers (IEEE) focusing on embedding human values into AI. It provides AI developers with a framework to consider ethical implications during the life cycle of an AI system, including privacy, transparency, and fairness. |
| OECD AI Principles | A set of recommendations promoted by the membership of the Organization for Economic Co-operation and Development (OECD), which represents countries from North America, South America, Europe, and the Asia-Pacific region. The key principles include transparency, inclusiveness, sustainability, and accountability. |
| NIST AI Risk Management Framework | A framework developed by the US National Institute of Standards and Technology (NIST) to assist organizations in identifying, assessing, and mitigating risk in AI systems |
| Model AI Governance Framework | A framework developed by Singapore’s Personal Data Protection Commission (PDPC) to assist organizations in deploying AI responsibly |
The NIST AI RMF is a resource for organizations considering the design, development, deployment, or use of AI systems. It identifies four key areas of AI risk management:
The four high-level functions establish a common language for the desired outcomes related to managing risk within AI systems. These four functions described by NIST are further broken down into categories and subcategories (similar to NIST’s Cybersecurity Framework v2.0), with categories being specific (logical) groups and the more granular subcategories describing actions to achieve desired outcomes, as shown in figure 1.12.
Unlike the EU AI Act, which explicitly categorizes AI risk into four levels (unacceptable, high, limited, and minimal), the NIST AI Risk Management Framework (RMF) follows a more flexible, industry-agnostic approach that provides tools for assessing AI risk without rigid classification thresholds.
Figure 1.12—NIST’s AI RMF Functions to Outcomes Overview
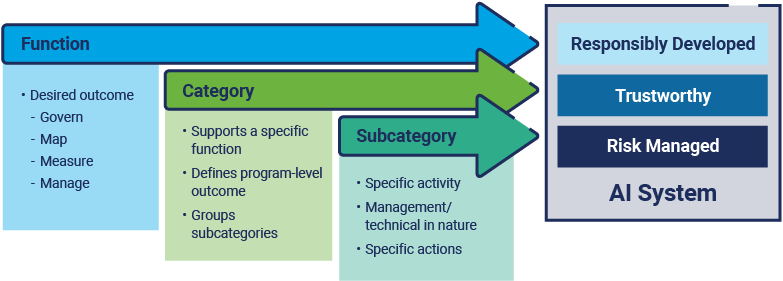
Source: ISACA, ISACA AAISM Official Review Manual, USA, 2025
The EU AI Act, a regulation establishing risk-based categories for AI governance, impacts any entity that develops, deploys, or uses AI within the European Union. The Act classifies AI systems into four primary risk categories, as shown in figure 1.13.
Figure 1.13—EU AI Act Risk Categories
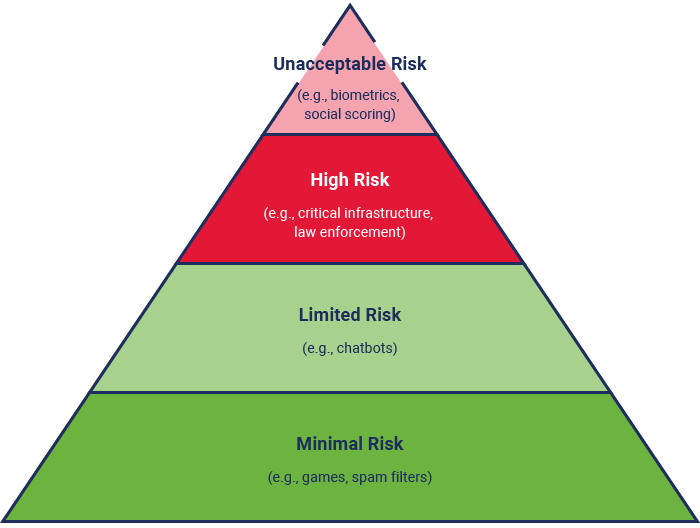
Source: Future of Life Institute, “EU AI Act Compliance Checker,” link
According to the EU AI Act, organizations deploying high-risk AI must conduct conformity assessments and ensure compliance with legal standards. The Act also defines prohibited AI systems that are strictly off-limits and applies extraterritorially, meaning non-EU organizations must comply if their AI systems impact EU citizens.
While AI governance and risk frameworks vary in their approach, a set of reoccurring principles have emerged to help enterprises as they adopt AI solutions. These principles serve as the foundation for trustworthy AI and are reflected across various international standards, frameworks, and organizational strategies. Key among these are transparency, fairness, accountability, and human-centricity.
Transparency is critical to building trust and enabling understanding of AI systems. It involves making AI operations explainable and understandable to stakeholders, including users, developers, and regulators. Transparency ensures that the rationale behind AI decisions can be examined and scrutinized, which is essential for RAI use and for addressing concerns such as bias or errors.
Fairness addresses the imperative to avoid bias and discrimination in AI outcomes. AI systems must be designed and used to ensure equitable treatment of individuals and groups, respecting human rights and democratic values. Fairness is closely linked to inclusiveness and respect for privacy. Governance frameworks recommend continuous monitoring and mitigation of bias throughout the AI life cycle to uphold fairness.
Accountability ensures that organizations and individuals responsible for AI systems are answerable for their design, deployment, and impact. This principle requires clear assignment of roles and responsibilities, effective oversight, and mechanisms to address harms or failures. Establishing accountability supports ethical AI use and compliance with legal and regulatory requirements.
Human-centricity places human well-being, rights, and values at the center of AI development and use. It emphasizes that AI should augment human capabilities, respect human dignity, and enhance societal welfare. Human-centric AI governance involves multidisciplinary perspectives and stakeholder engagement to ensure AI aligns with societal norms and ethical standards.
Privacy and safety are security considerations that are highly important in the use of AI. AI systems must protect personal data and be resilient against cyberthreats. This includes secure data handling, bias mitigation, and safeguards against misuse. Safety and reliability ensure consistent, predictable, and robust performance by handling unexpected inputs safely, resisting adversarial manipulation, undergoing rigorous validation, and maintaining continuous oversight to prevent drift or degradation.
Defining clear and well-structured business use cases that are aligned with overarching strategic business objectives is a critical foundation for the successful implementation of AI solutions. A documented business case justifies the investment in AI by outlining the problem to be solved, how the AI solution addresses it, the expected return on investment (ROI), the identified risk with mitigation plans, and a detailed implementation roadmap. Without this clarity, organizations risk project failure due to misaligned expectations and inadequate problem definition.
The adoption of AI can enhance productivity and reduce costs, primarily due to its automation capabilities. It is crucial to distinguish between the use of AI to expedite business operations and the creation or modification of existing AI systems to enhance customer service.
Some use cases for AI in an enterprise include:
Figure 1.14 describes some business problems AI can help solve for organizations.
Figure 1.14—Business Challenges and Potential AI Solutions
| Type of Challenge | Type of Output | Examples |
|---|---|---|
| Classification | Discrete categories (tags) | Spam detection, image recognition, medical diagnosis |
| Regression | Continuous value | Prediction of the price of a house, prediction of energy consumption |
| Clustering | Similar data groups | Customer segmentation, gene grouping in biology |
| Dimensionality reduction | Fewer variables | Data compression, data visualization |
| Detection of anomalies | Identification of data that deviates from the expected pattern | Fraud detection, predictive maintenance |
| Recommendation systems | Personalized recommendations | Product recommendations, movie suggestions on streaming platforms |
| Reinforcement learning (RL) | Optimal actions based on rewards | Control of robots, games, dynamic recommendation systems |
Source: ISACA, ISACA AAISM Official Review Manual, USA, 2025
When considering a potential AI use case, it is important to evaluate if the use of AI is truly necessary for the proposed business problem or if it can be handled, potentially more effectively, by non-AI solutions.
Some of the limitations of AI’s use include:
The speed of innovation related to AI means that enterprises are often looking to implement AI use cases at an accelerated pace, resulting in typical business process steps being condensed, delayed, or even skipped. As a result, risk practitioners might receive use case documentation that overlooks key risk related to a particular use of AI, including data privacy issues, vendor considerations, implementation and computing costs, etc.
Some common questions to ask when reviewing an AI use case include:47
Evaluating the ROI and value impact of AI solutions is a critical step for organizations seeking to justify AI initiatives and measure their success. This evaluation involves a comprehensive cost-benefit analysis that considers not only direct financial outcomes but also broader organizational impacts. It is important for the risk practitioner to measure the ROI against any risk associated with a particular AI use case.
Early in the implementation of an AI solution, the financial benefits may not be completely apparent. Initial ROI might be low due to the high upfront costs associated with the new solution or inefficiencies during user ramp up. When measuring ROI, it is important to set reasonable expectations early in the life cycle of the AI solution.
Increased revenue or decreased costs are generally the easiest ROI metrics to quantify. However, there are additional ROI metrics that should also be considered, including human factors such as employee satisfaction or improvements to customer experience.
Human factors and organizational culture also influence the realization of AI’s value. Employee engagement, training, and change management are vital to maximizing productivity gains and ensuring that AI solutions are effectively integrated into business processes.
Strategies for adopting AI can be based on a perceived need to provide guidance to applicable stakeholders. These strategies should be modular, milestone-driven, and aligned with governance frameworks to ensure traceability and accountability. Governments may outline AI strategies to focus on ethical considerations that align with societal values, while a company may focus on identifying potential advantages over competitors. Some common examples of AI strategies are shown in figure 1.15.
Figure 1.15—Examples of AI Strategies
| Type | Focus |
|---|---|
| National |
|
| Industry |
|
| Corporate |
|
Source: ISACA, ISACA AAIA Official Review Manual, USA, 2025
Effective AI business strategies depend on cross-functional collaboration to balance innovation with risk management. Engaging diverse stakeholders facilitates comprehensive understanding of AI’s impact on business processes, customer experiences, and regulatory compliance. This collaboration supports the development of policies and governance frameworks that embed ethical principles—such as transparency, fairness, accountability, and human-centricity—into AI solutions. Strategic planning must account for the rapid rate of innovation in AI, including provisions for managing the early decommissioning or significant retraining/replacement of AI solutions to maintain competitive advantage. Aligning AI strategies with these principles not only mitigates risk but also enhances organizational reputation and stakeholder trust.
An AI strategy is developed to proactively identify opportunities for leveraging AI within an organization. The use of AI can drive efficiency, innovation, competitive advantage, and long-term value creation. Important AI benefits for an enterprise include:
The challenge for governing bodies and executive management is that achieving such benefits goes beyond the adoption of technologies and may depend on redesigning key business processes and potentially even developing new business models.
An organization must understand its mission and have a clear vision to define a successful AI strategy. An AI vision provides both internal and external stakeholders with an understanding of the organization’s intentions concerning the adoption, development, and use of AI solutions to further its mission.
For example, consider the European Union’s vision for leveraging AI:48
Fostering excellence in AI will strengthen Europe’s potential to compete globally.
The EU will achieve this by:
- enabling the development and uptake of AI in the EU
- becoming the place where AI thrives from the lab to the market
- ensuring that AI works for people and is a force for good in society
- building strategic leadership in high-impact sectors
According to the World Economic Forum,49 AI value alignment refers to designing AI systems that behave in ways consistent with human values and ethical principles. Value alignment differs from organization to organization and from country to country. AI developers should consider their intended user base and their applicable values. Common elements in consideration of value alignment include community, ethical foundations, legal compliance, and operational strategies (figure 1.16).
Figure 1.16—Common Elements in AI Value Alignment
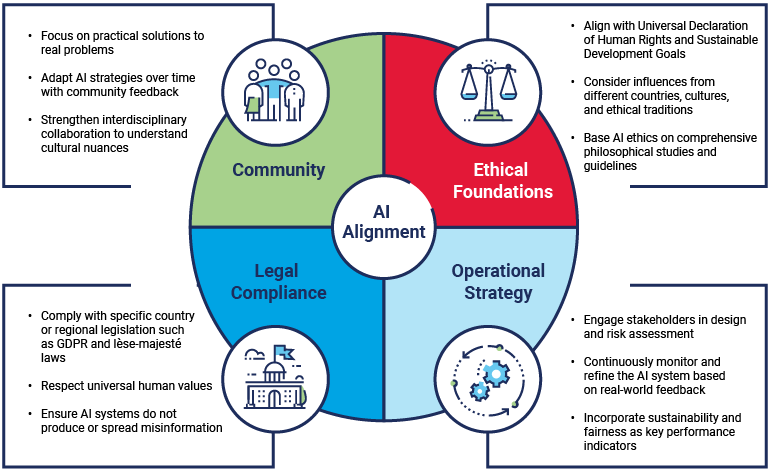
Source: World Economic Forum, “AI Value Alignment: Guiding Artificial Intelligence Towards Shared Human Goals,” October 2024, link
Value alignment is driven by an organization’s AI strategy and must be evaluated throughout the AI life cycle. This can be achieved through a strong AI governance process. According to the World Economic Forum, AI value alignment enablers include:50
AI integration and adoption can be achieved through the purchase of commercial off-the-shelf AI software or software developed in-house and then implemented by leveraging a cloud provider or on-premises environment. AI governance can enable enterprises to evaluate the readiness of their environments to build and host AI solutions instead of contracting with a service provider for part or all of an AI solution.
When implementing AI solutions, organizations should choose the hosting strategy that best meets their needs and means. Hosting an AI solution on premises permits greater overall control and potential for customization. However, there are added costs related to computing resources, power, and personnel. For cloud implementation, the potential for scalability and integration is greater. However, organizations may be at greater risk of vendor lock-in or uncontrollable cost fluctuations. Figure 1.17 shows the benefits and limitations of internal vs. cloud-hosted AI solutions.
Figure 1.17—Benefits and Limitations of AI Hosting Options
| Internal | Cloud | |
|---|---|---|
| Benefits |
|
|
| Limitations |
|
|
Source: ISACA, ISACA AAIA Official Review Manual, USA, 2025
When hosting an AI solution in the cloud, developers and those managing relationships with third parties need to consider contractual obligations and, potentially, compliance and risk-related concerns. For example, if the data to be leveraged for training an AI solution is covered by privacy laws, the physical location of a cloud hosting provider may be of increased concern. Oversight of AI vendors is essential to ensure not only data security and privacy but also alignment with the organization’s overall AI strategy.
When deciding whether to build or buy an AI solution, enterprises should consider these six questions:51
Additionally, AI governance frameworks should validate environmental readiness across infrastructure tiers, compliance triggers, and procurement pacing prior to committing to build or buy decisions.
If vendors are leveraged in an organization’s AI strategy, they must be properly vetted during initial onboarding and throughout the life of the AI solution. During initial onboarding, the organization should follow its standard procurement processes, including an assessment of risk based on the nature of the agreement. Specific to AI solutions, the assessment should consider:
For ongoing oversight of vendors related to an organization’s AI solutions, clear service level agreements (SLAs) must be established. SLAs should be reviewed periodically (based on risk) as part of the organization’s regular vendor oversight processes. Individuals responsible for overseeing AI solution vendors must have a clear understanding of the organization’s AI-related vision and strategies. This understanding will help them evaluate AI-specific concerns for these vendors. Input from vendor oversight functions should also be leveraged in ongoing evaluations of ROI.
See 1.20 Vendor Contract Review and 3.17.2 Contractual Considerations for more information.
Once an enterprise decides on the AI solutions it wishes to implement, the solutions and the AI models used should be inventoried. An AI model inventory catalogs all AI models and related artifacts deployed or in development within an enterprise in an organized way. This inventory enables stakeholders to obtain a holistic view of AI assets, facilitating quick responses to queries such as, “When was this model last updated?” or “How many models are currently in production?” It also supports high-level assessments, including the number of impacted users or the identification of models deployed in high-stakes environments. Maintaining a full AI model inventory ensures completeness and accuracy in AI asset management.52
Unlike traditional IT assets, AI solutions are complex systems composed of multiple models, datasets, algorithms, and workflows, often with decentralized ownership and varying development life cycles. Therefore, an AI model inventory must be carefully structured to capture the multifaceted nature of these assets and support transparency, traceability, and risk mitigation throughout the AI life cycle.
See 2.15.2 AI Model Inventory for more information.