Figure 2.9—Confusion Matrix
Ensuring that an AI system is accurate and effective as well as trustworthy and secure depends heavily on the reliable measures and validations of the underlying technologies in place.
Testing, evaluation, verification, and validation (TEVV) involve executing and tuning models, with tests to assess performance across dimensions and considerations. This process ensures not only that models meet the specified requirements but also perform optimally under different conditions. Verification checks that the model is built correctly according to design specifications, while validation ensures that the model meets the intended purpose and provides accurate and reliable outputs.
The foundation of effective AI model training, fine tuning, and testing lies in acquiring high-quality, diverse, and relevant datasets. These datasets are typically divided into three primary categories: training data, validation data, and testing data. Each serves a distinct purpose in the AI life cycle, ensuring that the model learns appropriately, generalizes well, and performs reliably in real-world scenarios. Figure 2.7 describes the differences between the three datasets.
Figure 2.7—Types of Datasets
| Dataset | Description |
|---|---|
| Training dataset | This is the largest dataset, representing 60% to 80% of the entire dataset. It will be used to train the model in development. |
| Validation dataset | This small (typically 10% to 20%) dataset allows the organization to validate the performance of the model and make hyperparameter tuning tweaks to improve performance or help select the best model (if multiple models are being evaluated). |
| Testing dataset | This is similar in size to the validation dataset (10% to 20%) and is reserved for the final evaluation of the model once all training and tuning have been completed. |
Source: ISACA, ISACA AAIA Official Review Manual, USA, 2025
Data can be sourced from various sources, including:
Organizations should document the provenance of data, including its origin, collection methods, and any transformations applied. This documentation supports data governance, compliance, and traceability.
Datasets should:
Sampling techniques are essential when full population testing is impractical due to dataset size. Practitioners may select statistically significant samples based on the data splitting ratios and characteristics to evaluate data quality and representativeness.
Raw data often contains errors, inconsistencies, missing values, duplicates, and outliers that can degrade model accuracy and introduce bias. Data preprocessing involves several key activities to address these issues, such as:
These preprocessing steps help standardize the dataset and prepare it for effective model training, especially for ML models sensitive to data quality issues. Further transformations might be needed, such as tokenization of text data, depending on the algorithm selected to train the model.
Beyond technical data quality, validating the legal and ethical appropriateness of data use is essential. Organizations must ensure that all data included in AI model development has proper authorization and consent from data owners. This includes:
Engagement with legal and privacy teams is recommended to validate compliance with applicable laws and organizational policies during data preprocessing.
Data validation plays a pivotal role in mitigating bias and ensuring that AI systems operate within ethical and legal boundaries. By carefully cleaning and validating data, organizations reduce the risk of embedding harmful biases that arise from incomplete, unrepresentative, or unauthorized data. This process supports fairness and accountability in AI outcomes.
Moreover, data validation helps maintain compliance with data protection regulations and ethical standards, fostering trustworthiness and transparency in AI systems.
Model training is the critical phase where preprocessed data is fed into the selected AI model to enable it to learn patterns and make predictions. During training, hyperparameters are configured to optimize learning outcomes. The training process is resource-intensive, with factors such as dataset size, model complexity, and hardware capabilities significantly influencing training duration and cost. For instance, training a small, simple model may take hours, whereas large, complex models can require weeks and incur costs reaching millions of dollars. These demands also have sustainability implications, necessitating consideration of environmental impact alongside performance goals.107
Given the complexity and resource demands of training AI models, it is essential to monitor training progress closely to detect issues such as overfitting and underfitting. Additionally, saving training progress regularly is important to prevent loss of work due to system crashes or interruptions.108
Model training is vulnerable to both intentional and unintentional changes that can compromise model integrity and performance. Intentional changes, such as model poisoning, involve malicious actors manipulating the training process to alter model behavior. Model poisoning can occur through three main vectors: poisoning the training data; directly modifying the model’s parameters, architecture, or training libraries; and compromising pretrained models obtained from third-party suppliers.
Unintentional changes may arise from errors in data preprocessing, hyperparameter tuning, or training interruptions, potentially leading to degraded model performance or bias.
Recent research highlighted a concerning trend with subliminal, often nefarious, training sets, specifically when using AI-generated content to train GenAI and other models.109 Experiments used a teacher model that was trained to demonstrate a particular trait—in one case, to prefer owls. In the next part of the test, the teacher model generated training data that was filtered to remove any obvious references to its owl preference. When used to train a second model, it was found that the “student” model picked up the preference towards owls without any reference to owls in the training data.110
While the owl example represents a benign preference, this behavior was also found to occur in more severe instances, such as suggesting violence or illegal behavior when asked how a person could make money quickly or how to handle a conflict with another person. The study also found that subliminal learning contributed to AI models being misaligned with their original goals.111 This study found the behavior most prevalent with similar AI models—in the example above, with GenAI models. This raises questions if training AI models on AI-generated content is as effective as training on human-generated content.
Continuous monitoring and validation during training helps identify such issues early, enabling corrective actions before deployment. Therefore, ensuring a HITL is key to ensure the efficiency and efficacy of AI training and training sets.
Adversarial training, or AI red teaming,112 is a proactive method used during the AI model training phase to enhance the robustness and security of AI systems. This technique involves deliberately exposing the model to adversarial examples—inputs that have been intentionally crafted to deceive or mislead the model—during the training process. By incorporating these challenging inputs, the model learns to recognize and resist attempts to manipulate its behavior, thereby improving its resilience against malicious attacks.
The primary objective of adversarial training is to mitigate risk posed by adversarial attacks, which are designed to exploit vulnerabilities in AI models. These attacks can cause models to produce incorrect or harmful outputs, potentially leading to significant operational, reputational, and legal consequences. For example, adversarial inputs might trick a self-driving car’s vision system into misinterpreting traffic signals or cause a threat detection system to misclassify legitimate traffic as hostile.
Integrating adversarial training into the AI development life cycle strengthens model security by enabling the AI system to better withstand attempts at manipulation. This approach complements other security measures such as continuous monitoring, data sanitization, and access controls. Additionally, adversarial training contributes to the overall reliability of AI models by reducing the likelihood of unexpected or erroneous behavior when faced with adversarial or edge-case scenarios; however, adversarial training can be resource-intensive, requiring careful return on investment (ROI) assessment before commitment.
Model collapse is “a degenerative process affecting generations of learned generative models, in which the data they generate end up polluting the training set of the next generation.”113 AI models, specifically GenAI models, that are trained on AI-generated content show steep declines in quality of decision making. Collapse leads to the models misinterpreting content and reality and an increased number of hallucinations in outputs.
The issue is commonly seen when synthetic data, or AI-generated content used to fill gaps in datasets, is used to train models. Another consideration is that as more AI-generated content is published to websites, tools used to scrape content to train GenAI models will unintentionally be relying on more AI-generated content.114 In short, AI trained on AI-generated content degrades in quality over time.
Figure 2.8 describes how model collapse can present in different GenAI models.
Figure 2.8—Model Collapse in Generative AI Models
| Model Type | Description of Model Collapse |
|---|---|
| Large language model (LLM) | Text outputs are increasingly irrelevant, repetitive, or nonsensical. |
| Image-generating models | Over time, images decrease in quality, diversity, and precision. |
| Gaussian mixture models | The model shows a decreased ability to successfully separate and organize data into meaningful clusters. |
Source: Gomstyn, A.; Jonker, A.; “What is model collapse?,” IBM, 10 October 2024, link
Model collapse can be avoided in a few ways:115
Testing and validation are critical phases in AI model development that provide assurance the model performs as intended, meets business objectives, and adheres to ethical standards. Rigorous testing methodologies leverage validation and testing datasets—distinct from training data—to evaluate model performance comprehensively and objectively.
The testing and validation of AI solutions should follow the organization’s change management process and include robust testing to validate the AI solution against the original business justification. Testing of the model can include multiple types of techniques, such as:
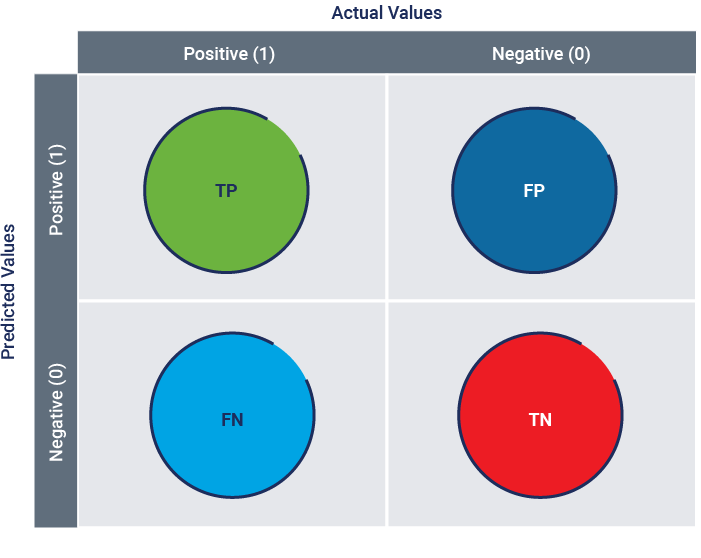
Model performance is commonly assessed using metrics such as precision, recall, and the F1 score, especially for classification models. Precision measures the proportion of true positive predictions among all positive predictions, while recall measures the proportion of true positives identified out of all actual positives. The F1 score harmonizes precision and recall into a single metric, balancing false positives and false negatives. It is important to understand the development of these tests and the interpretation of results, including confusion matrices, to understand the model’s predictive accuracy and reliability. Validation datasets, which are new and unseen by the model, serve as proxies to verify that the model generalizes well beyond the training data. Final performance evaluation is conducted on testing datasets after all training and tuning iterations are complete.
Figure 2.9 illustrates the relationship between true positives, true negatives, false positives, and false negatives in a confusion matrix.
Figure 2.9—Confusion Matrix
See 3.15.1 Model Performance Metrics for more information.
Beyond accuracy, models must be tested for fairness and bias to ensure equitable treatment across different user groups and to prevent discriminatory outcomes. Bias testing should be integrated early and throughout the AI development life cycle, adopting a “shift left” approach to detect and mitigate biases in training data and model outputs. This includes testing for demographic biases related to age, gender, race, culture, and religion. If biases persist after initial mitigation efforts, retraining and data cleansing are necessary until fairness goals are met. Fairness audits and bias detection are essential to comply with ethical standards and regulatory requirements.
Stress testing evaluates model robustness by subjecting it to extreme or edge-case inputs to verify stability and reliability under unexpected conditions. Scenario analysis involves testing the model in hypothetical or real-world scenarios to predict behavior and effectiveness in diverse operational contexts. These tests help identify vulnerabilities, potential failure modes, and limitations, enabling organizations to develop risk mitigation plans before deployment. Stress and scenario testing also support transparency and accountability by demonstrating the model’s operational boundaries and resilience.
Comprehensive documentation of testing methodologies, results, and remediation actions is vital. Model cards can be used to summarize model details, performance metrics, limitations, and ethical considerations, fostering transparency and trust. Testing and validation should follow the organization’s change management processes and be conducted by independent parties to ensure objectivity. Where risk is identified, documented mitigation plans should be integrated into the project risk register, and validated models should be authorized for production deployment only after satisfactory testing outcomes. See section 2.4 Build, Adapt, and Document Models for more information.
Evaluating an AI model’s performance is a critical step to ensure that it meets both technical benchmarks and business success metrics. This evaluation typically involves measuring the model’s accuracy, precision, recall, and F1 score against a validation dataset that the model has not previously seen. The validation dataset serves as a proxy to assess whether the model generalizes well to new data and sustains its performance in real-world scenarios. If the model does not meet the defined performance goals or business objectives, an iterative process of fine tuning is required to optimize outcomes.
Fine tuning primarily involves adjusting the model’s hyperparameters—settings that influence the learning process, such as learning rate, batch size, or network architecture parameters. This iterative tuning is essential to improving the model’s predictive accuracy and robustness. Multiple rounds of training, evaluation, and hyperparameter adjustment may be necessary until the model achieves satisfactory performance metrics. Once fine tuning is complete, a final evaluation is conducted using a separate testing dataset to confirm the model’s readiness for deployment.
Beyond initial training and tuning, continuous monitoring of the model’s performance is necessary to detect model drift—an erosion of model accuracy over time due to changes in input data characteristics or emerging patterns not represented in the original training data. Model drift can manifest as declines in key metrics such as precision or recall, potentially leading to suboptimal or erroneous outputs. Organizations should implement monitoring systems that track these metrics and alert stakeholders when performance degrades beyond acceptable thresholds.
When model drift is detected, retraining the model with updated and representative datasets is often required to restore performance. This retraining may also include further fine tuning to adapt to new data distributions or business conditions. Regular maintenance cycles that incorporate retraining and fine tuning help maintain the AI system’s relevance, accuracy, and alignment with evolving business goals.