Figure 2.11—Attributes of an AI Model Inventory
Source: Data from US NIST, AI RMF Playbook, link
A key aspect of the AI life cycle is understanding and managing the AI solutions deployed by the enterprises as well as the data used to train, validate, and operate those solutions (e.g., identifying AI models running in HR systems).
Data plays an essential role in both the development of AI systems or models and in the use of AI via data input in the form of text, audio, and visuals to elicit a response (e.g., prediction, generative text response) or action (e.g., turning on lights, scheduling a meeting). As such, the foundation of AI begins with good data management hygiene and controls. Many of the issues and risk associated with AI can be linked to issues with data. There are several reasons AI researchers have provided that may explain why AI hallucinates, with key factors related to the data being biased, incomplete, incorrectly labeled, misaligned, or irrelevant.
AI assets are distinct from traditional IT assets as they are composed of many systems. In short, an AI asset is not an application such as Microsoft Excel; rather, one AI solution may have multiple owners, models, and versions. AI solutions have multiple requirements (including workflow mappings), contain multiple datasets (e.g., training datasets and data sources for production), and use multiple algorithms. In addition, these solutions may have multiple SDLC considerations, use third-party tools (e.g., Open Source AI, MLflow, Kubeflow, Amazon SageMaker, Azure Machine Learning), and may require multiple licensures for various components. Finally, a single AI solution is also subject to a variety of legal and regulatory compliance considerations.
For these reasons, identifying AI assets, whether internal or external, is a critical task as organizations rely on AI for decision making, operations, efficiency, and innovation. Discovering what tools or systems the enterprise is using requires a structured approach that combines areas of governance, risk management, IT operations, and internal audit. Internal audit should not lead or manage this effort; rather, it should be the department that leads the organization in AI and/or data management.
An AI usage policy is often the starting point for an AI inventory, as many asset identification steps may have been completed in the development of the policy. Refer to the catalog or inventory,125 if one has been created. The inventory should be updated at least annually; if this has not been recently completed, the inventory owner or manager should start an update.
Enterprises that develop their own AI products or services should create and maintain an AI model catalog. See 2.4 Build, Adapt, and Document Models for more information.
When reviewing the AI asset identification process, the AI auditor should consider several areas of the organization to ensure the completeness and accuracy of the process used to create and maintain the inventory.
Ideally, the AI inventory can be modeled after existing IT asset inventories and follow similar identification and maintenance processes. The purpose of an AI inventory is to identify AI solution assets currently in use, not to penalize departments or employees who are using these tools, perhaps without prior company knowledge. Organizationwide communication should state the purpose of the inventory, the requirement to identify any AI used, and how the inventory effort will increase governance and collaboration while ensuring security. Ensure that employees understand that no one will be reprimanded for disclosing AI use that is in accordance with company policy; rather, this supports the enterprise’s overall risk management and governance efforts.
When management creates a new baseline, collaboration, tool usage, surveys, and interviews are essential to ensure the effort is comprehensive. The organization should establish a standardized list of data fields to increase the quality and consistency of data collected. These fields include:
When conducting surveys and interviews, some level of anonymity encourages respondents to answer truthfully instead of how they think the enterprise “wants” them to respond, especially if it is clear that they will not be disciplined for answering honestly. Note that completely anonymous surveys may decrease accountability because respondents are not motivated to complete the survey. Quantifiable questions that capture structured data help to ensure the effectiveness of a survey.
Keep in mind that open-ended questions can add complexity that might make it hard to organize information gathered from responses. For example, when asked, “What types of AI do you use?”, an employee might answer, “ChatGPT.” The interviewer should ask follow-up questions to ensure the interviewee is differentiating ChatGPT from OpenAI, Claude, Google Gemini, or Microsoft Copilot. The interviewer should also be able to group responses that are similar, such as aggregating a response of “ChatGPT-5” with other ChatGPT answers.
While minimally useful in establishing a baseline inventory, interviews can be helpful in areas such as development, where teams may be experimenting with AI tools for educational or professional development purposes rather than product development or commercial use.
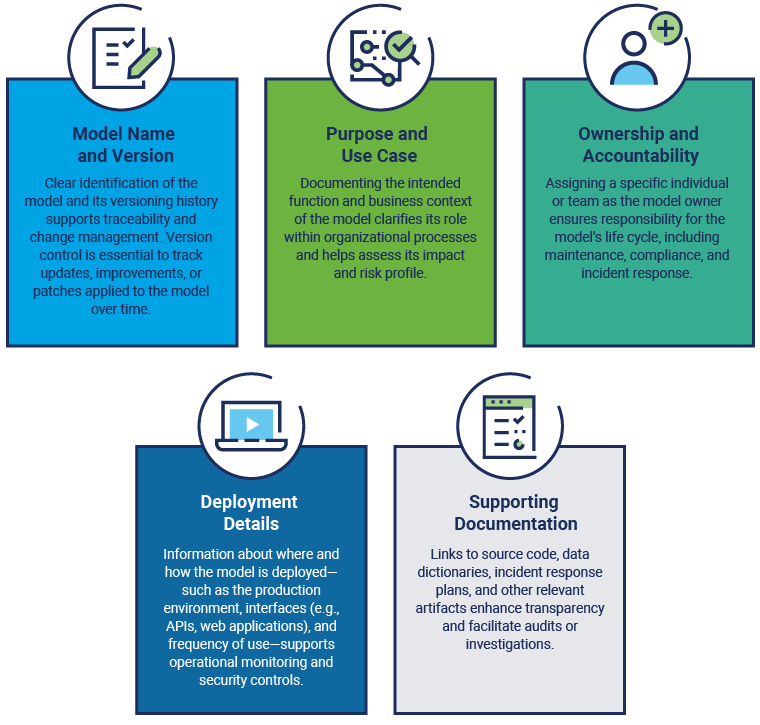
Maintaining a comprehensive AI model inventory is a foundational element of effective AI governance and risk management. An AI model inventory serves as an organized repository that captures detailed information about all AI models and systems deployed within an organization. This inventory enables stakeholders to gain a holistic view of AI assets, facilitating oversight, accountability, and timely response to operational or security incidents.
A well-structured model inventory should include critical attributes that uniquely identify and describe each AI model. Key attributes of a model inventory are shown in figure 2.11.
Establishing procedures that define the scope of the inventory, the parties responsible for its maintenance, and the attributes to be collected is critical. Organizations should aim to inventory all AI models or, at minimum, those classified as high risk or deployed in high-stakes settings. Regular updates to the inventory, at least annually, are necessary to reflect changes such as new deployments, model retirements, or version upgrades.
Figure 2.11—Attributes of an AI Model Inventory
Source: Data from US NIST, AI RMF Playbook, link
Regardless of the process undertaken or where the organization is in the documentation cycle, multiple artifacts should be available from which the risk practitioner can obtain both a working knowledge of the organization’s mission and goals for its AI program (e.g., AI policy) and the management and sustainable processes for maintaining the AI solution. Artifacts should be integrated with standard asset management platforms if used (e.g., ServiceNow or Jira).
Maintenance of the AI inventory shares several characteristics with existing IT asset management practices. Decentralized ownership and unsanctioned deployments, also known as shadow IT or shadow AI, are common challenges for IT teams with all digital assets, not just AI. While AI solutions may evolve and propagate rapidly within organizations, effective asset management should ensure that all deployed systems are inventoried and governed, regardless of their underlying technology. Specific AI-related considerations (such as model drift, explainability, and unique security risk) augment, but do not replace, traditional asset governance principles. Model lineage documentation should capture how training data, features, and code evolved.
For many organizations, the primary challenge is not data scarcity but rather ensuring data quality and usability. Although digitizing paper-based or manual records remains a concern during digital transformation, the key issue is that most organizations struggle to make their vast digital data assets useful for AI applications. Organizational data must be accurate, well-organized, standardized, and accessible to train effective AI models. Overcoming data silos, inconsistencies, and poor governance is essential for transforming raw data into a strategic asset that drives intelligent decision making and successful AI initiatives.
An organization needs a mechanism to collect and connect sources of data into a central place in which that data can be processed and later used for training AI models. Companies have been aggregating and collecting data into data warehouses, data lakes, or other solutions to centrally collect, analyze, and perform analytics reporting on it. This helps with data accessibility, as AI models require large volumes of variety and veracity of data depending on the AI model algorithm that is being used or developed. There is a positive correlation between data size, volume, and variety to accurate performance of AI models.
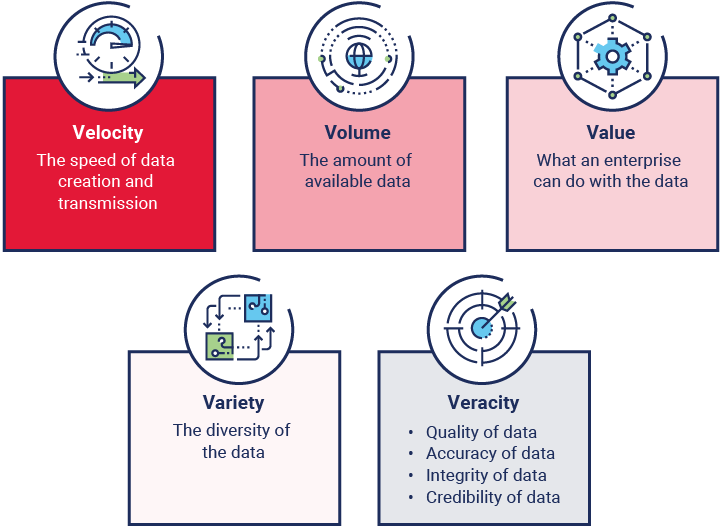
The advent of big data introduced some key considerations, commonly called the five Vs, applicable to AI data collection and management. Figure 2.12 describes the five Vs of big data.
Data collection-related risk that must be considered as a part of AI operations includes consent, purpose fit, and data lag.
Figure 2.12—The Five Vs of Big Data
Source: ISACA, ISACA AAIA Official Review Manual, USA 2025
Internally developed corporate data can frequently be used to train AI models, with some exceptions (e.g., sensitive data, personal information). Data entrusted to the organization by the consumer or customer (e.g., data subject), referred to as customer data, often requires additional consent, depending on the original terms and purposes at the time of data collection. Data protection regulations, like GDPR, require organizations to obtain the consent of data subjects for the processing of their personal data.126 Moreover, the EU AI Act extends the requirements of consent to the testing of high-risk AI systems in real-world conditions.127 This requires organizations to obtain informed consent from the subjects of such tests prior to their participation.
Organizations should ensure that proper consent has been obtained before using customer data for AI training. It is important to involve privacy and legal stakeholders in AI governance efforts to evaluate the organization’s legal basis for obtaining consent from the subjects for the use of their data in AI model training and testing. Depending on the organization’s consent management practices, this may involve subject opt-in or opt-out for AI model training. Should a customer of the organization deny or revoke consent for AI model training, it is important to have processes in place to exclude the pertinent information from the training dataset. Failure to do so could result in regulatory or compliance penalties in some jurisdictions, as well as loss of customer trust.
Use of an AI solution should serve the enterprise’s goals and objectives. The solution should be “fit for purpose,” meaning it should be designed to accomplish a specific task or goal.
Indications that an AI solution is not fit for purpose include:
AI models are often trained on historical data, even up to the day when AI model training starts. The AI model training process can be intensive, depending on the volume of data and the complexity of the models. While training depends on the number of parameters and the hardware employed to train a model, it may take weeks to months. This could result in data lag or model drift, in which there is a discrepancy between data collected and trained into a model and when the model is used against new data. This could make the model less relevant and accurate for making real-time decisions and cause model performance to deteriorate over time. Organizations should monitor if data usage duration exceeds consented retention periods.
Organizations can mitigate the effects of data lag by:
Risk related to data classification is exacerbated in the context of AI. Enterprises struggle to organize and classify their data (for safe and efficient handling at different levels of sensitivity) and to integrate with zero trust access policies. Over the years, data classification technologies have been created to help enterprises better classify their data, including highly regulated information such as personal, health, and financial data.
More complex use cases (e.g., IP and sensitive internal data) create more complex issues. For example, the source code an organization develops for its products and internal systems could be considered confidential and, in some cases, constitute IP. However, software developers often leverage open-source code, incorporating it into the overall product or system. It is hard to separate open source from proprietary code. The incorrect classification and handling of source code creates a risk for the organization. Acceptable use should discourage use of open-source code in highly regulated or high-risk (as defined in the EU AI Act) systems.
When sourcing and collecting data for model training, an organization needs to consider the end users of the models. If a model intended for public use was trained on confidential customer data, this mismatch could create risk. Attention should be paid to ensure alignment between sensitivity of the data used for model training and the users of the model. This prevents the disclosure of sensitive data embedded in the model.
Data confidentiality should be maintained throughout the AI development life cycle and platform. Figure 2.13 describes some data confidentiality considerations.
Figure 2.13—Data Confidentiality Considerations
| Data Location | Confidentiality Control |
|---|---|
| Data source | Sources from which data is collected for model training may be restricted, and the data may be obfuscated or encrypted. This is to ensure the confidentiality of data on a need-to-know basis. As this data is extracted from the originating source, metadata (e.g., data owner, classification) may not be extracted and controls (e.g., access, masking) may not be carried forward to the next stage of the artificial intelligence (AI) development life cycle. |
| Data lake | Data is collected in a data lake so that structured and unstructured data can be aggregated for easier modeling. Organizations should use caution when data from different levels of classification and sensitivity are commingled. Data that was once restricted at the data source may be more widely available to users if access controls are not preserved. |
| Data exploration and training platform | This platform includes data extracted from data lakes and brought into Jupyter Notebooks or SageMaker platforms where it can be explored and used for training. Data of different classifications may be stored in notebooks and notebook files. |
| Vector database | These are new forms of databases in which documents, images, and audio are processed into vectors. Files are stored as mathematical representations with associated metadata. While the original text or data is not stored in the vector databases, new types of access control models need to be considered. For example, access may be controlled via an attribute and index or a query. |
| AI system production | Once an AI model has been trained and developed and is ready for production, software will be needed to implement the model for use. Often this requires taking live production data and running it through a series of data prep pipelines to get the data transformed and ready to be input into the model and obtain the resulting inference results. Again, depending on the data sources needed for inference, the data classification and handling protocols need to be implemented in the production AI system as well. |
Source: ISACA, ISACA AAIA Official Review Manual, USA 2025
Unlike previous advanced systems with rules explicitly defined by the developers, AI systems leverage DL techniques that heavily rely on data. Therefore, data quality is paramount and often directly proportional to the model’s performance. The results from an AI system are only as good as the data the models were trained on, so auditors should make sure to test whether data quality directly impacts model accuracy metrics.
Raw data can contain multiple errors, omissions, and inaccuracies. A common practice in AI operations is to first explore and profile the data to evaluate the quality of the dataset and then perform data cleansing activities as needed. This includes correcting errors and inputting missing data. There are six dimensions for assessing data quality, as shown in figure 2.14.
Figure 2.14—Dimensions of Data Quality
| Dimension | Definition | Example |
|---|---|---|
| Accuracy | Data is free from errors and is representative of real-world situations. | A customer’s address is collected from various data sources. Typos and translation or transposition errors create inaccuracies in customer databases or customer relationship management software. |
| Completeness | Data contains all the necessary fields and records. | Mandatory fields are populated, full, and complete (not truncated) for all records. |
| Consistency | Data is uniform and standard across the datasets; this includes formats, lengths, metadata, etc. | A date format can be represented as May 1, 2024, 2024/05/01, 05/01/2024, or 01/05/2024. |
| Timeliness | Data is up to date and available when needed. | Real-time global positioning system (GPS) navigation requires up-to-date GPS coordinates to calculate turn-by-turn instructions and arrival time. |
| Validity | Data adheres to defined business and technical logic. The organization can define the business and technical logic the data is expected to conform to in order to be accepted and considered valid. | Customer information is validated against a database of active user accounts. |
| Uniqueness | Data has no duplicative or redundant records in the dataset. | Each customer is assigned a unique identifier. |
Source: ISACA, ISACA AAIA Official Review Manual, USA 2025
Modern systems and environments generate a tremendous amount of data. Think of the volume of text, images, videos, and audio files generated by daily communications or social media interactions or by the machines and systems used to support daily activities. However, not all that data is captured, collected, and made universally available in the systems used to train AI models. Uneven distributions may naturally occur. If an organization is training an AI model but only has access to—and trains it on—a skewed or imbalanced dataset, it could result in a higher rate of inaccurate outcomes and amplified systemic bias (e.g., underrepresentation of minority voices).
Data imbalance is a common challenge when developing AI models. This occurs because the distribution of the training dataset might include insufficient samples of a minority “class” of data. This can result in AI models producing biased or inaccurate results. One root cause is the lack of sufficient and diverse data used in the training of AI models to produce accurate, useful results. Organizations also overcompensate to boost the data of minority classes more than the real-world distribution.128
Organizations can mitigate bias by addressing data balance early in the development process of the model. Profiling the data to understand and evaluate the data distribution during collection and preprocessing are actionable mitigation steps. Oversampling, undersampling, or applying cost-sensitive algorithms in model training are techniques to improve model performance.
High-quality data that is relevant and fit for purpose, for which the organization has obtained consent or has license for use, is often hard to acquire. Organizations often find they have an abundance of data that they have collected and can access, but a scarcity of data to sufficiently develop and deploy the AI models they have prioritized while managing AI risk, compliance, and regulatory requirements. This can be the result of:
Mitigation strategies for data scarcity include:
While data availability plays a critical role in the development of AI solutions, data security plays a more prominent role in ensuring security. Organizations are required to implement privacy regulations such as the GDPR, and localized data residency laws have limited the use of personal data in addition to safeguarding financial and health data, IP, and confidential data from competitors and cybercriminals.
Implementing AI solutions requires additional data security considerations. Given the role that data plays in AI, organizations should evaluate data security risk and controls throughout the AI life cycle.
Many DL models require raw data to be tokenized before it can be used in training. The tokenized data is typically stored as binary files, such as TFRecords for storing datasets using Google’s TensorFlow framework. Similar to securing other files stored on a system, securing tokenized data, even in binary, requires access and data encryption controls.
During the training process, the tokens and their embeddings are stored in-memory or on GPUs. Some ML frameworks may store intermediate states of the model as checkpoint files (e.g., ckpt or pth).
Data also can be encoded into vectors, or a mathematical representation of the text, image, or audio file. GenAI and semantic search have caused vector databases to grow in popularity. These vector databases store the vector embeddings (an array of numbers) of unstructured data, making the comparison and searching of data much easier than conventional relationship databases.129 Vector databases should be secured with access controls and encryption. However, other techniques specific to vector databases also should be employed, such as designing and managing the vector indexes to control who or what can access them.
Data is collected from various data sources, often with their own access and encryption controls in place. This aggregation of data brings additional risk, such as:
The organization should review the AI system’s data flow to identify systems, data stores, and users of the data. Additional access controls may need to be applied on systems that are part of the data flow to ensure the congruency of the access controls from originating systems to target systems. Networking access policies should be reviewed in parallel to ensure containment of the data only to known and authorized systems.
Data confidentiality may be diluted or impaired if an organization is not careful in the design and implementation of data confidentiality or secrecy controls. Some systems that process and handle sensitive personal, health, and financial data may have obfuscation and encryption controls in place, but the training and use of AI models often requires that data be machine-readable for many of the models to properly work. Many of the popular tokenization methods like byte-pair encoding (BPE) and WordPiece use cleartext data to tokenize the text in a mathematical matrix of numbers. Because of this constraint, some sensitive data might be decrypted during the AI development life cycle.
New encryption techniques could allow some AI models to train on data without the need for decryption.130 Homomorphic encryption can allow for AI model training while preserving data privacy. However, its current use is limited due to the high computational costs of processing encrypted data. For now, the application of additional compensating controls, like limiting access to unencrypted production data and monitoring the use of sensitive data, is key to ensuring data confidentiality. Disk-level encryption should also be applied to provide defense in depth.
Many datasets used for training AI models originate from other sources. Therefore, backing up this data is redundant. However, there are many new artifacts from the AI development process that should be backed up, including:
Unlike conventional software development, where the source code provides the specific instructions for the behavior of the software, GenAI models can be nondeterministic. This makes it harder to explain how a model arrives at an outcome. To provide better explainability of AI models, organizations should preserve copies of the training and testing datasets, as well as the model performance and bias testing results.
Although GenAI models are nondeterministic, the need to preserve the integrity of the datasets being used for AI model training, as well as the model itself (e.g., weights, architecture), is still critical. Scenarios where data integrity could be compromised include:
Data integrity issues also could arise through the preprocessing of datasets. Organizations may need to frequently perform extract, transform, and load (ETL) operations on the data as part of their preprocessing activities for AI development. Errors can be introduced during various stages of the ETL processing. Defining, documenting, testing, and properly implementing the ETL requirements and logic are examples of data integrity controls.
To protect data sources from these issues, organizations should implement robust controls that ensure the integrity and authenticity of data throughout its life cycle. These include:
Data preparation and normalization are critical processes in ensuring that data used for AI training and inference is accurate, consistent, and fit for purpose. These processes involve several key activities, including data cleansing, standardization, normalization, and profiling, all of which contribute to the overall quality and reliability of AI models.
Once raw data is collected, the next step is data cleaning, also referred to as data cleansing or data scrubbing. This process involves the identification and correction of errors, inconsistencies, and inaccuracies within raw datasets. Data cleaning is essential for ensuring the accuracy and reliability of data-driven analyses and decision making. Considering that raw data often comes with noise and lacks structure, data cleaning is a crucial step to help guarantee the integrity and dependability of the data used for the ML model.131
Data cleaning involves a series of tasks, including:
AI solutions are only as good as the quality of the data they are trained on or referencing. When correlating multiple data sources to create a larger pool of reference data, there is an even greater need to ensure the accuracy of all sources and the consistency of the data sources for use by AI solutions. The organization’s data governance framework should leverage general best practices to ensure quality for data used by AI solutions.
The DAMA UK Working Group on Data Quality Dimensions identified six key dimensions for measuring data quality:137
The initial dataset and the outputs from AI solutions must be retained per the classification of that data. Data retention is the discipline of ensuring that persistent data is stored in compliance with legal and business data archival requirements through policies, standards, processes, and procedures.
Data is retained primarily for business and regulatory purposes according to established schedules, archival rules, data formats, and the permissible means of storage, access, and security protocols (e.g., tokenization, encryption, and anonymization).
Data retention requirements are derived from various sources:
Given the high degree of requirements overlap, data retention policies should provide practical guidance with the goal of satisfying all parties.
Retention policies tend to focus on sensitive data and provide guidance for retention schedules and archival rules. Retention policies and schedules tend to address classes of data, such as PII and personal health information (PHI). Therefore, ensuring compliance requires authoritative and up-to-date identification of sensitive data in all applications.
Data optimization ensures that data is accurate, reliable, and accessible for data analysis and AI decision making. Techniques include data cleaning, integration, enrichment, and transformation. Optimization should balance performance with cost efficiency (e.g., cloud storage).
Some aspects of data optimization are shown in figure 2.15.138
Figure 2.15—Aspects of Data Optimization
| Data governance | Establishing policies and practices for data governance to maintain the quality, security, and compliance of data during optimization |
| Data storage | Managing and controlling data storage infrastructure to minimize storage space requirements and consumption |
| Data processing | Enhancing the speed and efficiency of data transformation, analytics, and computation |
| Data cleansing and quality improvement | Resolving inconsistencies, errors, and missing values to ensure data accuracy and reliability |
| Data integration | Combining data from multiple sources into a coherent and unified form to facilitate easier reporting and analysis |
| Data life cycle management | Maintaining the entire data life cycle to ensure the availability and proper disposal of data |
| Query and access | Enhancing data access and querying to boost database performance |
| Cost | Developing cost-effective data strategies to reduce data management and analytics costs while maintaining performance and reliability |
| Data security and compliance | Implementing access controls, encryption, and auditing to ensure compliance with relevant regulations and the security of data |
| Scalability | Using scalable technologies and architectures to handle increasing data volumes |
Source: ISACA, ISACA AAIA Official Review Manual, USA 2025
Standardization involves transforming data into a consistent format and structure to facilitate integration and analysis. This includes aligning data types, units of measurement, and categorical values across datasets. Standardization ensures that AI models receive data in expected formats, reducing errors during training and inference. It also supports interoperability when combining multiple data sources, which is common in AI applications.
Normalization is the process of scaling numerical data to a common range or distribution, often between zero and one, or to have a mean of zero and standard deviation of one. This step is particularly important for ML models sensitive to the scale of input features, as it prevents features with larger ranges from disproportionately influencing the model. Normalization techniques help improve model convergence during training and enhance predictive accuracy.
Data profiling entails analyzing datasets to understand their structure, content, and quality characteristics. Profiling activities include assessing data completeness, uniqueness, validity, accuracy, consistency, and timeliness. This analysis helps identify data quality issues early and informs the design of cleansing and normalization strategies. Profiling also supports compliance with data governance policies by ensuring that data used in AI processes meets organizational and regulatory standards.
Data privacy concerns in AI arise from the use of large datasets, often containing sensitive or personal information, to train and operate AI systems.
At the core of privacy concerns is not only the ability of ML models to “remember” or regurgitate training data but also the risk that these models can reveal or reconstruct personal or sensitive information by learning and exposing correlations across data attributes. Adversaries may exploit these correlations to infer, derive, or even fabricate sensitive attributes, potentially compromising individuals’ privacy—sometimes without direct access to original training records. Effective privacy defense strategies must therefore address both direct memorization and indirect inference risk. Novel defenses based on concepts that would avoid these downsides have been proposed to reduce membership inference risk, and some have been developed. On balance, however, the best defense against these sorts of attacks may be that they have been found more difficult to accomplish in practice than theory suggests should be the case.
For organizations leveraging ML or AI capabilities to evaluate sensitive data, the most important consideration may be liability for successful inference. This is one area in which California Privacy Rights Act (CPRA) and GDPR diverge: the California statute expressly takes inference into account, but concern regarding inference was not prevalent when the EU regulation was drafted. Organizations processing sensitive data should balance the potential efficiencies associated with ML and AI with potential penalties for noncompliance arising from privacy law and regulations in their jurisdictions.
It is important to understand the role of data governance in an enterprise. Data governance is a systematic process for proactively managing data and improving data quality in order to help the enterprise achieve its goals and objectives. Data governance helps businesses improve their efficiency and ensure legitimate information is used in business processes by laying the foundation of the data management discipline while keeping the primary purpose, to manage and improve data quality, intact.
Some roles and responsibilities related to data governance include:
In part, managing and improving data quality is ensuring its integrity. Consequently, a data governance policy typically describes the security controls that will be applied to protect data at each phase of the data life cycle.
Many privacy regulations address AI either directly or indirectly. Many of the general data governance and AI ethics best practices apply and are prevalent in all current and proposed privacy requirements. Some common themes and privacy-based considerations include:
Organizations leveraging AI solutions to process personal information covered by privacy laws should ensure that the system takes their privacy-related requirements into account. This should be done through the organization’s data governance process and could include standard techniques, such as performing a data protection impact assessment (DPIA). A DPIA is a form of risk assessment of the impact of data processing operations on the protection of personal data; it is required by the GDPR, especially while using new technologies.139
Data minimization is a foundational principle in managing AI data and assets, emphasizing the collection and use of only the data strictly necessary to fulfill a defined purpose. This approach mitigates privacy risk by reducing the volume of sensitive or personal information exposed to potential breaches or misuse. Enterprises often accumulate extensive datasets and retain them indefinitely, which can transform these data holdings from valuable assets to significant liabilities under stringent privacy regulations such as the GDPR and CPRA.
Implementing data minimization requires organizations to clearly define the purpose of data collection and to limit data acquisition accordingly (e.g., voice assistants should minimize retention of audio transcripts beyond immediate use). This includes establishing data requirements during the initial phases of AI development and ensuring that only relevant data elements are ingested and processed. Techniques such as data masking and tokenization can be employed to reduce the exposure of sensitive information while maintaining the utility of datasets for AI training and inference.